|
|
| (24 intermediate revisions by 3 users not shown) |
| Line 1: |
Line 1: |
| A well-organized data folder reduces the risk for many types of errors. At DIME, we have a standardized folder structure. Some projects have special folder requirements and only use the folder set up as a starting point, but many resources created by DIME are easier to take advantage of if this template is followed. It takes a lot of work to reorganize a project folder, so we strongly recommend that projects follow our standard from the beginning. A poorly set up folder will have inefficiency consequences and increases the risk of errors over several years.
| | The DataWork folder is a structured, standardized data folder that increases project efficiency and reduces the risk of error. The DataWork folder houses all files related to a project’s data, including data files; questionnaires; data collection documentation; code for sampling, treatment assignment, and [[Data Analysis | analysis]]; analysis output; and survey, monitoring, [[Administrative and Monitoring Data | administrative]], and secondary data. DIME strongly recommends using the DataWork folder from the beginning of the project and throughout its duration. |
| | |
| We have published a command called [[iefolder]] in our package [[Stata_Coding_Practices#ietoolkit|ietoolkit]] that we have published on SSC. [[iefolder]] sets up the recommended folder structure described in this article for you.
| |
|
| |
|
| == Read First == | | == Read First == |
| * Do not set up these folders manually. [[iefolder]] is a Stata command that easily sets up and updates this folder structure for you. | | * Use the <code>[[iefolder]]</code> Stata command to easily set up and update the DataWork folder. |
| | *Many DIME resources are easier to take advantage of when the DataWork folder is used. |
| | *Use the DataWork folder from the beginning of the project: reorganizing a project folder is time-consuming and cumbersome. |
| | *Even if your project has special structural requirements, use the DataWork folder as a starting point. |
| | == Creating the DataWork Folder == |
| | [[File:FolderBox.png |thumb|350px|Image 1. Example of where the DataWork folder is in relation to Box/DropBox folders. (Click to enlarge.)]] |
|
| |
|
| == Where should the DataWork folder be created? ==
| | The DataWork folder is easily set up via the Stata command <code>[[iefolder]]</code>, which is part of the package <code>[[Stata_Coding_Practices#ietoolkit|ietoolkit]]</code>. |
| [[File:FolderBox.png |thumb|350px|Image 1. Example of where the DataWork folder is location in relation to Box/DropBox folders. (Click to enlarge.)]] | |
|
| |
|
| Most project folders are shared across the project teams using DropBox, Box, or something similar. In this folder, there are different folders for project budget, government communications, etc. DIME's folder structure template assumes 'the ''DataWork''' folder to be one of them.
| | The DataWork folder should be housed within the project folder, which contains a variety of other sub-folders (i.e. project budget and government communications). The DataWork folder and the broader project folder should be shared across project teams via [https://www.box.com Box], [https://www.dropbox.com/ Dropbox], or a similar platform. Image 1 shows a DataWork folder housed within a project folder. |
|
| |
|
| See Image 1 on the right with an example of a Box/DropBox folder with three project folders. All three projects have a similar sub-folder structure, but in the image only one of the projects sub-folder structure is shown. The '''DataWork''' folder is highlighted with a red circle.
| | == Contents == |
| | [[File:Datawork.png |thumb|300px|Image 2. Example of a DataWork folder. (Click to enlarge.)]] |
|
| |
|
| Anything related to the data of a project has a designated location inside this folder. This includes data-files, sampling and treatment assignment code, questionnaires, data collection documentation, analysis code, analysis output etc. This includes data collected by ourselves, both regular survey rounds and monitor data, and also includes other sources of data such as admin data or secondary data.
| | The DataWork folder contains a [[Master Do-files|master do-file]], Survey Round folders, a Survey Encrypted Data folder, and a Master Data folder. It may also contain additional documentation (i.e. readme) to help users navigate its contents. |
|
| |
|
| == Inside the DataWork folder == | | === Master Do-File === |
| [[File:FolderDataWork.png |thumb|300px|Image 2. Example of a DataWork folder. (Click to enlarge.)]]
| |
|
| |
|
| Inside the '''DataWork''' folder there should only be folders and a [[Master Do-files|master do-file]] or perhaps also other documentation that helps navigating those folders. The folder structure in the image is a template that we recommend for all projects, although we understand that some projects have special requirements and therefore will only use this as starting point. Everything described here is easily set up using the Stata command [[iefolder]].
| | The project [[Master Do-files|master do-file]] runs all other project do-files from cleaning to final analysis. It also sets up dynamic file paths so that multiple users can work from the same project folder shared via, for example, Dropbox or Box. This ensures that everyone gets the same results. |
|
| |
|
| The ''DataWork'' folder should have a folder we call '''EncryptedData''' where files with sensitive data should be put and can be encrypted, a folder we call '''MasterData''' where we keep documentation and data sets that track the observations we are collecting data on, a '''project master do-file''', and '''survey round folders''' where the data for each survey round is stored. The survey round folders can be organized into subfolders for complex projects with a large number of surveys. All of these items are explained below.
| | If you are new to a project folder, always start by finding the master do-file: it serves as a map of all files in the DataWork folder. |
|
| |
|
| === EncryptedData === | | ===Survey Rounds=== |
| This folder create a branch in the ''DataWork'' folder that can easily be encrypted using an encryption software like boxcryptor. Anything identifying or in any otherway sensitive data, should be saved in this folder. Note that while [[iefolder]] helps you create a folder called ''Encrypted Data'' when you set up the ''DataWork'' in the first place, iefolder does not encrypt it. Later, when creating either a new survey round or new unit of observation (Master Data) with iefolder, the command creates folders for each survey round or unit of observation in the ''EncryptedData'' folder where raw data, high frequency checks and other items likely to have identifying or other sensitive information should be stored.
| | [[File:FolderSurveyRound.png |thumb|300px|Image 3. Example of a Survey Round folder. (Click to enlarge.)]] |
| | |
| === MasterData ===
| |
| After the project folder is set up initially, there are two types of folders, neither of them yet created, where the data for the project should be stored. One type is [[DataWork_Folder#Survey_Round|Survey Rounds]] and this is where data in relation to a specific data collection is stored. This is explained in more detail below, but a survey round is typically baseline, endline etc. The other type that will be discussed here is the [[DataWork_Folder#Master_Data|Master Data]]. A project need one master data set for each [[Unit of Observation|unit of observation]] used in the project, for example, households, students, teachers, firms, etc.
| |
|
| |
|
| In a master data set we store information about all the observations we collect data on. This should be more than just the sample that we end up using in our data collections. This should also include observations in a census not sampled for the project or observations not in the sample that we still encounter in monitoring activities. This is important as we are sometimes needed to be able to identify observations that are not in our sample, not just the observations that are. In these master data folder we can track any time-invarient information that could be needed across our project, such as observation in sample, which assigned treatment status, monitoring information such as in treatment uptake, identifying information etc. The data sets where we store this information are called '''Master Data Sets'''.
| | Each [[DataWork Survey Round | Survey Round]] folder contains a master do file specific to its data source, in addition to the following folders: [[DataWork Survey Round#DataSets Folder|DataSets]], [[DataWork Survey Round#Dofiles Folder|Dofiles]], [[DataWork Survey Round#Outputs Folder|Outputs]], [[DataWork Survey Round#Documentation Folder|Documentation]], and [[DataWork Survey Round#Questionnaire Folder|Questionnaire]]. While the folders listed here are <code>[[iefolder]]</code>, you can also create more folders that are unique to your project. |
|
| |
|
| When adding a new unit of observation using [[iefolder]], folders are created both inside the encrypted branch of the ''DataWork'' folder and outside it. In the encrypted branch we can store any information, but the version of the master data set in the ''MasterData'' folder outside the encrypted branch should have all identifying information removed. The reason we have an decrypted version as well is that it is quicker to access and it can often be shared outside the research team.
| | ====What Requires a Survey Round Folder?==== |
| | Each source of data (i.e. baseline, follow-up, midline, endline, [[Administrative and Monitoring Data | administrative]], secondary) should have its own Survey Round folder within the DataWork folder. If the data source is collected continuously (i.e. administrative or secondary data as macro data over time), then it requires only one Survey Round folder. However, if the data source is collected in stages (i.e. baseline and endline data), then it requires one Survey Round folder for each stage. |
|
| |
|
| ==== Sampling and Treatment Assignment ====
| | If you have multiple [[Unit of Observation|units of observation]] in a given data source, each unit of observation for each data source requires its own Survey Round folder. For example, if the units of observation during baseline data collection are students, teachers and schools, then baseline data requires three Survey Round folders: ''baseline_students'', ''baseline_teachers'' and ''baseline_schools''. If you choose, these folders may be nested within a parent ''Baseline'' folder. <code>[[iefolder]]</code> gives you the option of doing this by creating a ''Baseline'' subfolder and then creating Survey Round folders within it. |
|
| |
|
| The master data sets folder should also include all activities that is best practice to do directly on the main listing of all observations. The two best examples of such tasks in the context of Impact Evaluation is sampling and treatment assignment. This should never be done directly on census data or baseline data etc. Census data will be used for sampling, but the point here is that we always want to match the census data to the master data and check that it makes sense in relation to whatever data we have there already. After that quality control step, we can sample directly from the master data set knowing that the sample we randomize will make sense in relation to other data sources.
| | Note that each Survey Round needs to have a unique name across the project when using <code>[[iefolder]]</code>. |
|
| |
|
| === Project Master Do-File === | | === Survey Encrypted Data === |
| The DataWork folder should also have a ''project master do-file''. A [[Master Do-files|master do-file]] is a do-file that runs other do-files needed to everything from cleaning to analysis and it also set same settings for all users making sure that everyone gets the same result. A very useful side effect of a master do-file running all other do-files is that it works as a map to where all files are located in the DataWork folder. If you are new to a project folder, always start by finding the master do-file.
| |
|
| |
|
| The project master do-file sits in the DataWork folder, but each round folder has a round master do-file as well. The round master do-file has the same purpose but only for the files and folders associated with that round. A master do-file is also used to set up dynamic file paths so that multiple users can work from the same project folder shared over, for example, DropBox or Box. See the article on [[Master Do-files|master do-files]] for more details.
| | Whenever you create either a new survey round or new unit of observation with <code>[[iefolder]]</code>, the command creates a partner folder for each survey round or unit of observation in the Survey Encrypted Data folder. Any identifying or sensitive data should be saved in the Survey Encrypted Data folder; the folder’s contents can easily be [[Encryption | encrypted]] using software like [https://www.veracrypt.fr/en/Home.html VeraCrypt], we previously recommended Boxcryptor but securoty issues were found in that software so we strongly recommend against using Boxcryptor. . Note that while <code>[[iefolder]]</code> creates the Survey Encrypted Data folder, it does not encrypt it. |
|
| |
|
| ===Survey Round===
| | Consider, for example, a master dataset. The version with identifying information should be stored in the Survey Encrypted Data folder. The version [[De-identification | without identifying information]] should be stored in the Master Data folder. The latter version is quicker to access and can often be shared outside the research team. |
| --------
| |
|
| |
|
| [[File:FolderSurveyRound.png |thumb|300px|Image 3. Example of a Survey Round folder. (Click to enlarge.)]] | | === Master Data === |
| | [[File:FolderMasterData.png |thumb|300px|Image 4. Example of a Master Data Set folder. (Click to enlarge.)]] |
|
| |
|
| Baselines, Follow Up Surveys, Midlines, Endlines are all examples of a Survey Round. But other types of data sources also fits in Survey Rounds in this project folder template. Those types could be monitor data or admin data. Each survey round is a source of data. If that source is collected continuously (like admin data or secondary data as macro data over time) then only one survey round is needed, but data sources that are collected in stages (like household data collected in both baseline and later in endline) there should be one Survey Round created for each stage.
| | The Master Data folder stores information about all the observations for which data is collected, including observations both in and out of the sample. As it is sometimes necessary to identify observations outside of the sample, the Master Data folder should also include, for example, |
| | *Census observations not sampled for the project, or |
| | *Observations encountered in monitoring activities but not in the sample. |
| | In the Master Data folder, we can also track any time-invariant information relevant to the project (i.e. assigned treatment status, treatment uptake, identifying information, dummy for being sampled). The datasets where we store this information are called [[Master Data Set |master datasets]]. |
|
| |
|
| Each survey round should have it's own sub-folder inside the '''DataWork''' folder. This folder, the sub-folders discussed here and a round master do-file are created automatically if you use [[iefolder]]. For example - Inside the main data folder, you can have sub-folders like baseline, follow up 1, follow up 2, midline, endline, etc. See image 3 for an example.
| | A project needs one master dataset for each [[Unit of Observation|unit of observation]] used in the project (i.e. households, students, teachers, firms). |
| | |
| Inside each Survey Round folder you have a master do file for that survey round as well as the following folders [[DataWork Survey Round#DataSets Folder|DataSets]], [[DataWork Survey Round#Dofiles Folder|Dofiles]], [[DataWork Survey Round#Outputs Folder|Outputs]], [[DataWork Survey Round#Documentation Folder|Documentation]], and [[DataWork Survey Round#Questionnaire Folder|Questionnaire]]. You can create more folders that are unique to your project, but these are the standardized folders that [[iefolder]] creates for you.
| |
| | |
| See [[DataWork Survey Round]] for more details.
| |
| | |
| ==== Multiple Units of Observation in a Survey Round ====
| |
| | |
| If you have multiple [[Unit of Observation|units of observations]] in a survey round, for example farmers and village leaders, or students, teachers and schools, then you should create a survey round folder for each unit of observations for each round of data collection. For example, you would end up with one survey round folder called ''baseline_students'', one called ''baseline_teachers'' and one called ''baseline_schools''. [[iefolder]] gives you the option of creating a subfolder that wou could call baseline and create all baseline survey rounds ''baseline_students'', ''baseline_teachers'' and ''baseline_schools'' in it. Note that each survey round needs to have a unique name across the project when using [[iefolder]].
| |
|
| |
|
| ==== Sampling and Treatment Assignment ==== | | ==== Sampling and Treatment Assignment ==== |
|
| |
|
| Sampling and Treatment Assignment folders have intentionally been left out from the survey round folders. Separate folders for those tasks has been created in the master data set folder as we strongly recommend that sampling and treatment assignment is done directly from the master data sets.
| | The Master Data folder should also include all activities performed on the main listing of all observations (i.e. sampling and treatment assignment). This should never be done directly on census data or baseline data etc. While census data will be used for sampling, it is important to match the census data to the master data and check that it makes sense in relation to whatever data exists there already. After that quality control step, sample directly from the master data set, knowing that the randomized sample will make sense in relation to other data sources. |
| | |
| === Monitor Data ===
| |
| | |
| Monitor data is data collected to understand the implementation of the assigned treatment in the field. Typically, survey round data helps us understand if any changes in the outcome variables under the duration of the project, and monitor data helps us understand how these changes are related to the intervention of our treatment. For example, monitor data could be data on who actually received the treatment and if the treatment was implemented according to the research design. Our analysis might be invalid if we do not have this information and base our analysis only on what was meant by the research team to happen. Monitor data helps us understand what is usually referred to as [https://en.wikipedia.org/wiki/Internal_validity internal validity].
| |
| | |
| For the purposes of DIME's project folder template, Monitor Data should be treated as a survey round of its own. However, sometimes survey round data and monitor data are collected in the same data collection, and then it is not feasible to keep them separated.
| |
| | |
| === Admin Data ===
| |
| | |
| Admin data is data that are usually collected by other actors, often for other purposes, but has been shared with the research team. It can be used both in the way survey round data is used in the analysis or as the way monitoring data can be used. For example, if the outcome variable the research team is trying to evaluate is measured in some other way then that is admin data we can use to measure change in outcome data. One example would be standardized test scores. We can often use the internal data our implementation partner uses as monitor data. That is one example when admin data is monitoring data. There are also many cases when the same admin data set is used for both purposes.
| |
| | |
| Create a new survey round folder for admin data sets.
| |
| | |
| ===Master Data===
| |
| --------
| |
| | |
| [[File:FolderMasterData.png |thumb|300px|Image 4. Example of a Master Data Set folder. (Click to enlarge.)]]
| |
| [[Master_Data_Set#Master_Data_Set_Folder|Master Data Sets]] is the best tool to avoid errors related to using multiple sources of data for one project. All impact evaluations use multiple sources of data. Multiple survey rounds are in this sense different sources of data. A census made before a data collection is a different source of data. Monitoring data and admin data combined with any other data are other examples. Master data sets should therefore be used in all projects and [[iefolder]] therefore creates the main folders for Master Data Sets by default when the ''DataWork'' folder is created.
| |
| | |
| There are two locations where Master Data Sets are stored. One location inside the encrypted brach of the ''DataWork'' folder. Here you can save a Master Data Set with identifying information. In not other data set than here will we have both the ID variable as well as identifying information. This is the key between the IDs that we use and the identity of the respondents. If this data set is shared publicly, then the identity of all of our respondents are revealed.
| |
| | |
| The Master Data Sets is a listing of all observations we have ever encountered in relation to this project (not just the observations we sampled). In this listing, we keep identifying information and the unique ID that we have assigned. We also keep time invariant information required at multiple stages of the research work. Examples are dummy for being sampled in baseline, categorical variable for treatment arm, dummy for correctly receiving the assign treatment arm etc. See the [[Master_Data_Set|Master Data Sets]] article for more details.
| |
| | |
| Master Data Sets is more than just a folder. It is a methodology for internal research validity in a multi data set environment. See the [[Master Data Set|Master Data Sets]] article for information both on how the master data set folder should be organized but also how it should be used for research quality purposes. One important motto is that if you do any merge (string or numeric) where the variable you merge on is not a proper ID variable, then one of the data set you are merging should always be a master data set.
| |
|
| |
|
| == Back to Parent == | | == Back to Parent == |
| This article is part of the topic [[Data Management]] | | This article is part of the topic [[Data Management]] |
|
| |
|
| [[Category: Data Management ]] | | == Additional Resources == |
| | *DIME Analytics' guidelines on [https://github.com/worldbank/DIME-Resources/blob/master/welcome-iefolder.pdf iefolder] |
| | *DIME Analytics’ [https://github.com/worldbank/DIME-Resources/blob/master/stata1-3-cleaning.pdf Data Management and Cleaning] |
| | *DIME Analytics’ [https://github.com/worldbank/DIME-Resources/blob/master/stata2-3-data.pdf Data Management for Reproducible Research] |
| | [[Category: Data_Management ]] |
The DataWork folder is a structured, standardized data folder that increases project efficiency and reduces the risk of error. The DataWork folder houses all files related to a project’s data, including data files; questionnaires; data collection documentation; code for sampling, treatment assignment, and analysis; analysis output; and survey, monitoring, administrative, and secondary data. DIME strongly recommends using the DataWork folder from the beginning of the project and throughout its duration.
Read First
- Use the
iefolder Stata command to easily set up and update the DataWork folder.
- Many DIME resources are easier to take advantage of when the DataWork folder is used.
- Use the DataWork folder from the beginning of the project: reorganizing a project folder is time-consuming and cumbersome.
- Even if your project has special structural requirements, use the DataWork folder as a starting point.
Creating the DataWork Folder
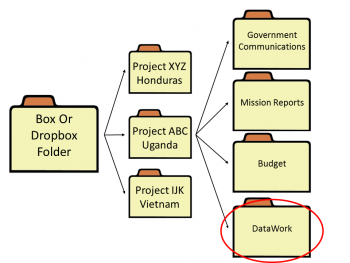
Image 1. Example of where the DataWork folder is in relation to Box/DropBox folders. (Click to enlarge.)
The DataWork folder is easily set up via the Stata command iefolder, which is part of the package ietoolkit.
The DataWork folder should be housed within the project folder, which contains a variety of other sub-folders (i.e. project budget and government communications). The DataWork folder and the broader project folder should be shared across project teams via Box, Dropbox, or a similar platform. Image 1 shows a DataWork folder housed within a project folder.
Contents
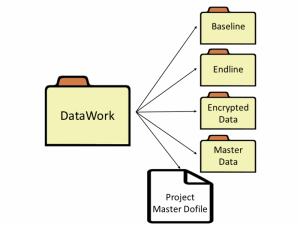
Image 2. Example of a DataWork folder. (Click to enlarge.)
The DataWork folder contains a master do-file, Survey Round folders, a Survey Encrypted Data folder, and a Master Data folder. It may also contain additional documentation (i.e. readme) to help users navigate its contents.
Master Do-File
The project master do-file runs all other project do-files from cleaning to final analysis. It also sets up dynamic file paths so that multiple users can work from the same project folder shared via, for example, Dropbox or Box. This ensures that everyone gets the same results.
If you are new to a project folder, always start by finding the master do-file: it serves as a map of all files in the DataWork folder.
Survey Rounds
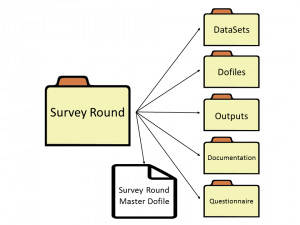
Image 3. Example of a Survey Round folder. (Click to enlarge.)
Each Survey Round folder contains a master do file specific to its data source, in addition to the following folders: DataSets, Dofiles, Outputs, Documentation, and Questionnaire. While the folders listed here are iefolder, you can also create more folders that are unique to your project.
What Requires a Survey Round Folder?
Each source of data (i.e. baseline, follow-up, midline, endline, administrative, secondary) should have its own Survey Round folder within the DataWork folder. If the data source is collected continuously (i.e. administrative or secondary data as macro data over time), then it requires only one Survey Round folder. However, if the data source is collected in stages (i.e. baseline and endline data), then it requires one Survey Round folder for each stage.
If you have multiple units of observation in a given data source, each unit of observation for each data source requires its own Survey Round folder. For example, if the units of observation during baseline data collection are students, teachers and schools, then baseline data requires three Survey Round folders: baseline_students, baseline_teachers and baseline_schools. If you choose, these folders may be nested within a parent Baseline folder. iefolder gives you the option of doing this by creating a Baseline subfolder and then creating Survey Round folders within it.
Note that each Survey Round needs to have a unique name across the project when using iefolder.
Survey Encrypted Data
Whenever you create either a new survey round or new unit of observation with iefolder, the command creates a partner folder for each survey round or unit of observation in the Survey Encrypted Data folder. Any identifying or sensitive data should be saved in the Survey Encrypted Data folder; the folder’s contents can easily be encrypted using software like VeraCrypt, we previously recommended Boxcryptor but securoty issues were found in that software so we strongly recommend against using Boxcryptor. . Note that while iefolder creates the Survey Encrypted Data folder, it does not encrypt it.
Consider, for example, a master dataset. The version with identifying information should be stored in the Survey Encrypted Data folder. The version without identifying information should be stored in the Master Data folder. The latter version is quicker to access and can often be shared outside the research team.
Master Data
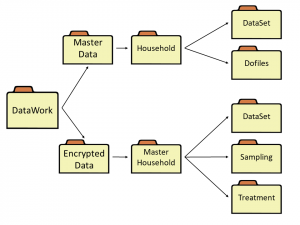
Image 4. Example of a Master Data Set folder. (Click to enlarge.)
The Master Data folder stores information about all the observations for which data is collected, including observations both in and out of the sample. As it is sometimes necessary to identify observations outside of the sample, the Master Data folder should also include, for example,
- Census observations not sampled for the project, or
- Observations encountered in monitoring activities but not in the sample.
In the Master Data folder, we can also track any time-invariant information relevant to the project (i.e. assigned treatment status, treatment uptake, identifying information, dummy for being sampled). The datasets where we store this information are called master datasets.
A project needs one master dataset for each unit of observation used in the project (i.e. households, students, teachers, firms).
Sampling and Treatment Assignment
The Master Data folder should also include all activities performed on the main listing of all observations (i.e. sampling and treatment assignment). This should never be done directly on census data or baseline data etc. While census data will be used for sampling, it is important to match the census data to the master data and check that it makes sense in relation to whatever data exists there already. After that quality control step, sample directly from the master data set, knowing that the randomized sample will make sense in relation to other data sources.
Back to Parent
This article is part of the topic Data Management
Additional Resources




